Queries#
In Shapelets, data is stored in DataFrame-like data structures of type dataset. These are tabular structures with an index, rows and columns, in which data is stored.
In order to access data stored in Shapelets datasets, you can execute SQL queries directly or, alternatively, you can write queries in python using a simple syntax based on list comprenhensions.
If you know how to operate with lists, you know how to operate Shapelets datasets and you don’t need to learn anything. Learn more about list comprehensions here.
For this section, we’ll start by loading a well-known dataset, the iris dataset. We will do this using the load_test_data() function.
>>> import shapelets as sh
>>> session = sh.sandbox()
>>> data = session.load_test_data()
>>> data.head()
Sepal_Length Sepal_Width Petal_Length Petal_Width Class
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
Note
Remember to create Shapelets session first to work with Shapelets smart storage system.
Shapelets Syntax#
Shapelets has a very pythonic API, so if you know how to code in Python you will move very fast with Shapelets.
You can use the map() function in order to write list comprehension queries to interact with the data.
>>> session.map(x for x in data)
However, if you are more familiar with SQL or feel more comfortable using SQL syntax, you can use the execute_sql() function which will help you access any file and write SQL queries.
>>> r = session.execute_sql(f'SELECT * FROM {data.alias} LIMIT 10')
The object that return
>>> r = session.execute_sql(f'SELECT * FROM {data.alias} LIMIT 10')
The object that return
>>> r = session.execute_sql(f'SELECT * FROM {data.alias} LIMIT 10')
The object that return execute_sql function is a Shapelets DataSet object.
Selecting Data#
Shapelets provides a function called map() in which we can write list comprehension loops that will be used to query the dataset.
For example, to get all the rows, you can use:
>>> session.map(x for x in data)
>>> session.map(x for x in data).head()
Sepal_Length Sepal_Width Petal_Length Petal_Width Class
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
The map() function returns a DataSet. This code will return all rows with all columns.
This functions give you the same result if you execute a SELECT * FROM TABLE query in a classical SQL Database.
If you want to select single columns, you can do:
>>> # Select Sepal_Width and Petal_Width columns from dataset.
>>> session.map((x.Sepal_Width, x.Petal_Width) for x in data)
>>> # Select Sepal_Width and Petal_Width columns from dataset.
>>> session.map((x.Sepal_Width, x.Petal_Width) for x in data).head()
Sepal_Width Petal_Width
0 3.5 0.2
1 3.0 0.2
2 3.2 0.2
3 3.1 0.2
4 3.6 0.2
What about filters? If you want select data using a filter, you only need an if statement in your list comprehension. Here is an example:
>>> # Select rows that Petal_Length > 1.4
>>> session.map(x for x in data if x.Petal_Length > 1.4)
>>> # Select rows that Petal_Length > 1.4
>>> session.map(x for x in data if x.Petal_Length > 1.4).head()
Sepal_Length Sepal_Width Petal_Length Petal_Width Class
0 4.6 3.1 1.5 0.2 Iris-setosa
1 5.4 3.9 1.7 0.4 Iris-setosa
2 5.0 3.4 1.5 0.2 Iris-setosa
3 4.9 3.1 1.5 0.1 Iris-setosa
4 5.4 3.7 1.5 0.2 Iris-setosa
If we want to sort the results of a query, we can use the sort_by() function of a dataset and specify by which column(s) we want to sort.
This functions receive two params, the columns you want to sort the dataset, and a boolean param to indicate whether you want an ascending or descending order.
By default, this method sort the results in ascending ordering.
If you want an ascending order, pass a string with the column name to the function.
>>> # ascending order
>>> data.sort_by('Sepal_Length')
If you want a descending order, pass a string with the column name to the function.
>>> # descending order
>>> data.sort_by('Sepal_Length',False)
If you want to combine, or sort by multiple columns, just pass lists with the values to the function.
>>> data.sort_by(['Sepal_Length','Petal_Length'],[False,True])
Note
You can visualize the results using the functions explained in Contents of a DataSet
Aggregate Data#
In order to compute some statistics for our data grouping by some columns, in a SQL-based syntax you would typically use the GROUP BY statement.
In Shapelets, the syntax for querying data are list comprehensions, so you only need to call agregate functions in the list comprehension to get a group by clause. For example, if you want to get the average of a column grouping by another column that has string values, you can do it this way:
>>> from shapelets.functions import avg
>>> session.map((x.Class, avg(x.Sepal_Length)) for x in data)
>>> from shapelets.functions import avg
>>> session.map((x.Class, avg(x.Sepal_Length)) for x in data).head()
Class avg(x."Sepal_Length")
0 Iris-setosa 5.006
1 Iris-versicolor 5.936
2 Iris-virginica 6.588
You can see the complete list of aggregation functions in the API Reference.
Manipulate Data#
Add a column#
In Shapelets you can add/append a new column to the Dataframe using the add_column() function.
>>> data.add_column('new_feature', lambda row: row.Sepal_Length*row.Sepal_Width)
In this example we create a new column as the result of multiplying two existing columns.
Rename a column#
You can rename a column using rename_columns()
>>> data.rename_columns({'Sepal_Length':'Lenght_sepal'})
Remove a column#
You can remove a column using drop_columns()
>>> data.drop_columns(['Class'])
Getting a subset of columns#
You can select a subset of columns using select_columns() function. Here’s an example:
>>> data.select_columns(['Sepal_Length','Petal_Length'])
Also, you can pass to the function indexes of columns like:
>>> data.select_columns([0,2])
In addition, you can do it using the map() function selecting the column that you want like
>>> session.map(x.Sepal_Length, x.Petal_Length for x in data)
Note
You can visualize the results using functions viewed in Contents of a DataSet
Join Data#
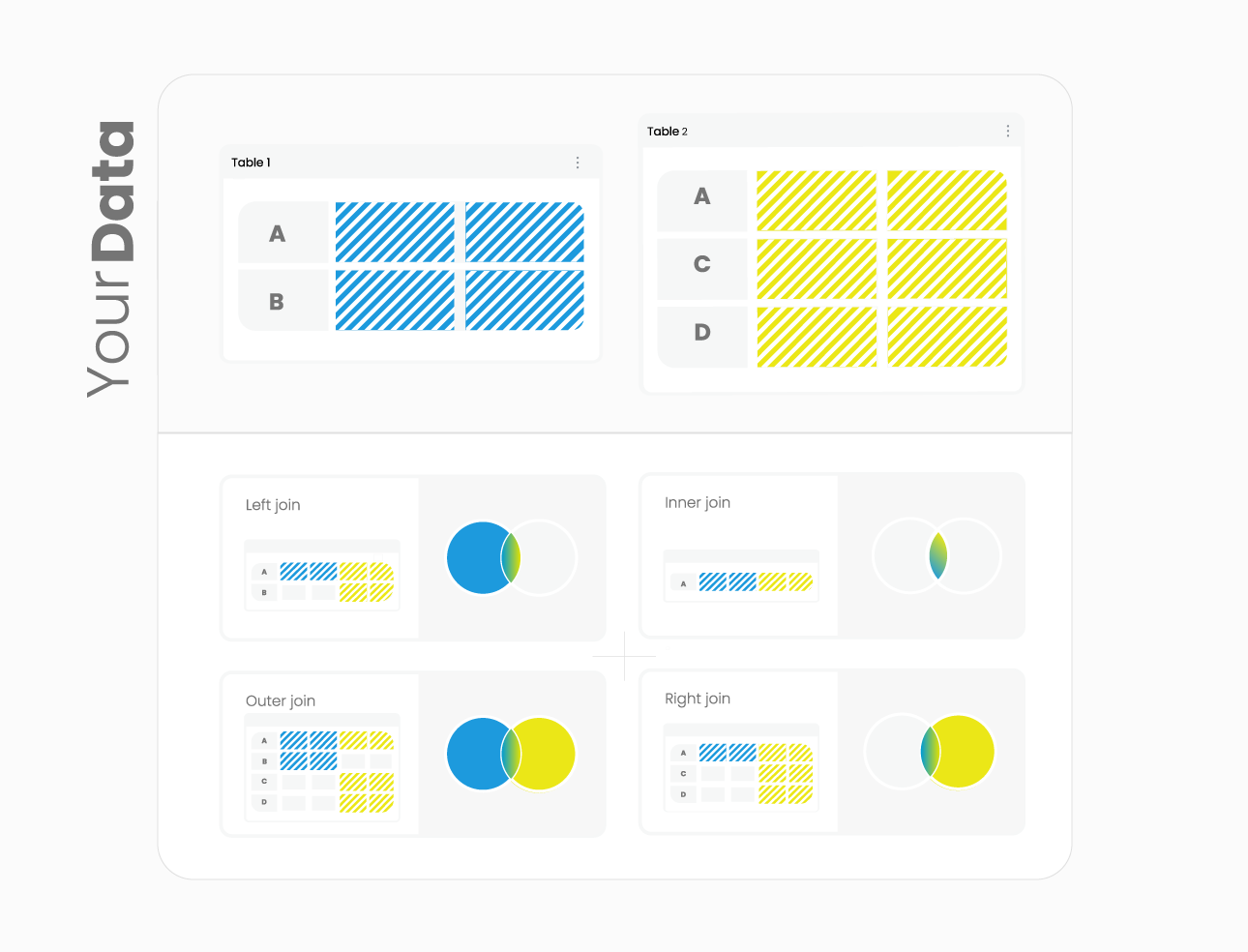
Shapelets provides a way for easily combining different datasets. Let’s see this with examples! First, we need a new dataset to join with our dataset.
>>> import pandas as pd
>>> df_uses = pd.DataFrame({'Class':['Iris-setosa','Iris-versicolor','Iris-virginica'],'common_uses':['Unknown','Stimulating','Creating ointments']})
>>> df_uses
Class common_uses
0 Iris-setosa Unknown
1 Iris-versicolor Stimulating
2 Iris-virginica Creating ointments
>>> uses_dataset = session.from_pandas(df_uses)
In general, there are different ways of joining tables such as: left join, right join, inner join, outer join or full join. Let’s see these with some examples.
If you want to join current dataset a new dataset, you can do for example a full join like this
>>> session.map(
>>> (x.Class, y.common_uses)
>>> for x in data
>>> for y in uses_dataset
>>> if (x.Class == y.Class)
>>> )
If you want another kind of join, for example a left join you should use the left() function with the dataset that you want to merge. Here is an example:
>>> from shapelets.functions import left
>>>
>>> session.map(
>>> (x.Class, y.common_uses)
>>> for x in data
>>> for y in left(uses_dataset)
>>> if (x.Class == y.Class)
>>> )